SinGAN
1. Introduction

i. Problem Define
- Unconditional Image Generate 를 이용해 High Resolution을 생성하는 일은 굉장히 큰 발전을 이루어 오고 있다.
- 그러나 여러 클래스가 한꺼번에 들어와 있는 경우는 여전히 도전대상이다. (e.g : Image Net 등)
- 이런 사진의 경우 input signal( Guided를 말하는건가?)이나 다른 task에 얽매여 생성 할 수 있다.
ii. Contribution

- Single Image만으로도 학습이 가능함을 강조
- Bidirectional patch를 사용하여 조작 된(Manipulated) 이미지의 패치가 원래의 패치와 동일하도록 적용
- Single Image로 다양한 task를 진행한다 (Paint to Image, Editing, Harmonization, S-R, Animation)
- 단 하나의 모델로 (물론 트레이닝은 다양하게) 이 모든 task가 가능함
2. Related works
i. Single Image Deep Models

이 그림에서 처럼 textual를 패턴처럼 사용하지 않는다는 것을 보여주는 figure
- 특별한 task에 맞게 “overfit”되지 않은 순수한 generative model이다 (S-R이나 texture에 맞게 생성하는 RW을 예로듬 )
- 그리고 Unconditional GAN들은 대부분 context나 textual에 의존하여 이미지를 생성했지만 our model은 그렇지 않음 (Fig.3)
ii. Generative models for image manipulation
- 주 도메인이라 생략함
3. Method
-
textual generate를 넘어 정말 일반적인 자연 이미지를 표현하기위해 이미지의 복잡하고 다양한 Statistics를 여러 크기의 이미지에서 학습해야한다고 함.
-
그러기 위해서는 이미지의 배열과 object들의 모양 등 전체적(Global)한 특징과 object들의 detail한 정보 textual 등 특징들을 모두 배워야함.
-
이를 위해 Multiscale 구조를 사용했음
i. Multi-scale Architecture
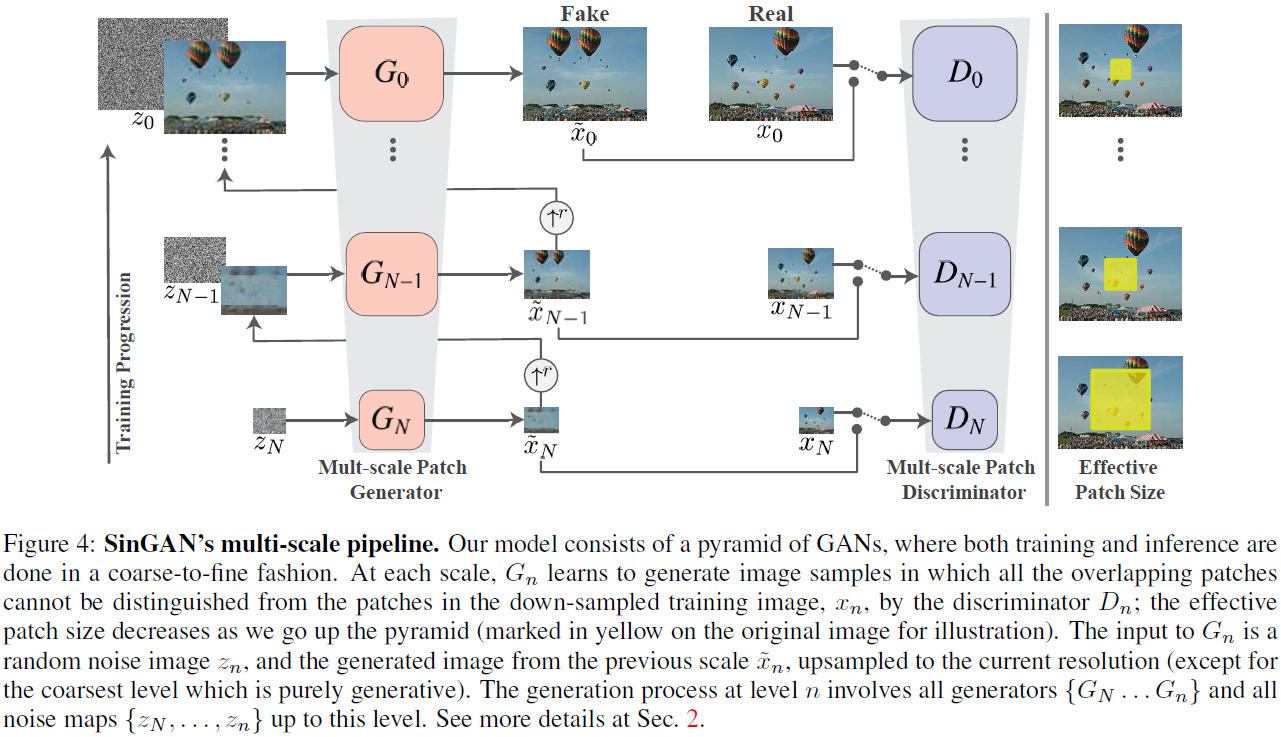
SinGAN Architecture
-
모델에는 Generator {G_0, … , G_N} 까지의 구성으로 되어있고, input image x_0는 downsampling 되어 x_N까지 이루어져 있다 ( r은 downsample을 실행하는 factor로 r>1)
-
각 Generate와 Discriminate는 그림과 같이 multi-scale로 이루어진다.
-
Generator는 작은 scale에서는 Global한 이미지를 중점적으로 생성하고, 큰 scale에서는 detail한 fine한 요소들을 중점적으로 생성한다.
-
Discriminator는 scale의 변화에 따라 Effective한 patch size가 달라지게 되고 마찬가지로 큰 scale과 작은 scale에 따라 원활한 학습이 가능해진다. -> 즉, 알아서 상대방(Generator)에 맞게 형성된다고 보면 됨
ii. Training
- Training은 수식과 같이 Adversarial loss와 Reconstruction loss로 나누어져 있다.
Advarsarial Loss
WGAN-GP loss를 사용했고 이는 model의 stability를 올리는 역할을 했다. Discriminator에는 11x11의 patch size를 사용함
Reconstruction loss
generator가 생성한 image와 그 단계의 Ground truth 이미지의 차이를 줄이기 위해 squred loss를 사용했다.
각 단계별로 주입되는 noise 셋팅은 reconsturction loss part 에서는 첫 단계를 제외하곤 주입하지 않았다.
Discriminator를 속일 수 있을 때 까지 방해요소를 최대한 줄여보자는 의미인 것 같음(Hoya blog 댓글)