SPatially-Adaptive-DEnormalization
1. Introduction

- Image synthesis할 때, Semantic segmentation을 포함한 상황이라는 특정 상황에 관심이 있었다고 한다.
- 이런 task를 할 때 정규화 레이어들이 Sementic mask들의 정보를 “Wash away”하는 경향이 있다는 문제를 발견하고 이를 해결하고자 함.
- 지금 이해하기로는 기존에 있던 Sementic mask에 새로운 Sementic mask가 들어오면 기존 정보를 씻어버리고 새로 써내려간다 그렇게되면 주변 입력과는 상관없이 자연스럽지 못하게 되어버린다.
2. RW는 생략
3. Sementic Image Synthesis
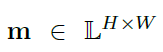
-
semantic segmentation mask 을 나타냄
-
L은 sementic label(river, mountain, water, tree …)
-
H,W은 height width
a. SPatially-Adaptive DEnomalization(SPADE)
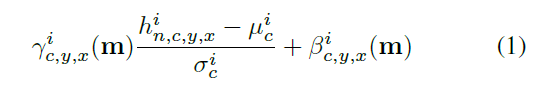
-
h^i는 Convolution레이어 중 i번째 레이어에 N개의 batch sample이 주어지면 되는 활성화 값
-
C^i는 Convolution레이어 중 i번째 레이어의 channel
-
평균(μ)에 표준편차(σ)로 나눈 값에 정규화 된 레이어에서 학습된 weight값을(감마,베타) 곱하고 더해주는게 SPADE
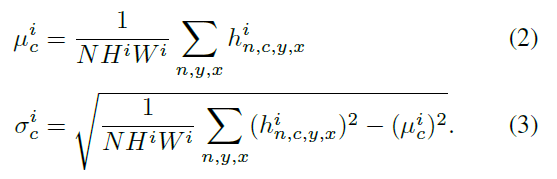
-
각 c(channel),y(height),x(width)에서 scaling과 bias 값을 나타내는 평균,표준편차
-
SPADE를 이용하므로서, 각 segmentation mask를 이미지 클래스 라벨로 대체하면서 변조된 파라미터 공간을 고정시키게 되면 Conditional BN과 같아진다고 한다.
-
공간적(국지적?)으로 변형이 없다면 Conditional BN으로 reduce하게 되고, 공간적 값을 고정하고 N을 1로 설정한다면 AdaIN(Adaptive Instance Normalization)이 된다.
-
결론적으로 SPADE가 하는 역할은(내가 이해하기로는) 국지적인 부분에서 Sementic Segmentation을 이용한 Image sythesis에서 좀 더 자연스럽게 합성이 가능하게 만드는 역할이다.(부분값을 교체하고 적응시켜가며)
-
어찌보면 SPADE는 자연스럽게만 해주는 것인듯, 자연스럽게 만든다면 그것 자체가 Photo realistic함
b. SPADE Generator
-
처음 입력(우측그림 맨 앞)시에는 Segment information이 필요하지 않다.
-
각 블럭은 ResnetBlock을 사용했고, 사이사이 SPADE를 끼워넣어 preserve를 강화했다.
-
Pix2PixHD의 기법인 Multi-scale-Discriminator를 사용했고, 전체적 loss function또한 Pix2PixHD의 기법을 대부분 가져옴.
c. Why dose SPADE work better?
-
일반 nomalize layer보다 더 기존의 sementic 정보들을 보전을 잘하기 때문
-
기존에 SoTA로 쓰이는 InstanceNorm이 경우에는 flat하거나 uniform 한 마스크의 경우에는 정보를 wash away한다.
-
기존에 특정 sementation mask로 모든 픽셀을 도배하고 다른 균일 한 값을 가진 레이블로 올리면 기존 정보가 wash away하기 때문에 정규화 된 활성화 값이 모두 0이된다. (보전 X)
-
즉, 정리하자면 SPADE를 이용한 방법들은 기존 Normalization을 이용하는 이유인 “적응(Adaptive)”에 키워드를 맞추고 “부분적으로 적응시키며” -> “어색함을 야기하는 Wash Away를 보완”
d. Multi-modal synthesis
-
Multi-modal인 이유는 real image와 이게 없을경우 random vector로 그냥 처리할 수 있기 때문이다.
-
real-image의 경우 Encoder에서 generator로 convolution을 진행한 뒤 넘겨주고(코드에서 확인), random vector 의 경우 그냥 들어감
4. Experiments (Metric 위주로)
a. Dataset은 생략
b. Performance Metrics
i. mIoU(mean Intersection-over-Union)
- 잘 만들어진 sementic segmentation의 출력은 GT의 라벨에 맞게 생성된다(뭔말?)
- mIoU는 IoU의 평균을 의미하는듯, IoU는 두 영역의 교차영역을 합영역으로 나눈 수치. 클 수록 정확도가 좋다는 뜻
ii. accu(Pixel accuracy)
- 픽셀당 해당 값에 대한 정확도 클 수록 정확도 좋음
iii. FID(Frechet Inception Distance)
- 나중에 포스트 예정