1. Introduction
- Face Reenactment의 조건을 설명함
a. Photo-realistic face
b. pose & expression Seqeunce를 자연스럽게 만들어야함
c. One shot or Few shot으로
- Problem setting

a. 모든 부분적인 View에 있어서 한 사진만을 가지고 생성할 수 있어야하는 문제 b. 1개의 이미지는 1개의 pose&expression을 가지고 있기 때문에 그것을 다른것으로 변형하는데 커버해야할 부분에 대한 문제 c. Identity preserving
- Key
a. Disentagle b. composing appearance and shape information
- Goal
a. 얼굴 확인과 같은 어려운 작업에서 배운 얼굴 표현은 좋은 후보로 보입니다. 그러나 우리의 실험은 저수준 텍스처 정보를 잘 유지할 수 없다는 것을 보여줍니다. (뭔말일까) b. face reconstruct를 할 때 pose와 expression을 배제하고 해야한다는 것 (Shape-independent face appearance) c. natural gap이 test와 training사이에 존재함. 이유는 training과 test에 사용되는 이미지가 다르니깐 당연한 것
2. RW는 넘어감
3. Approach
- Overview
§ input face x를 F : X -> A(appearance) 와 E : X -> B(representation) 로 출력
§ Decoder를 통해 D : B x A -> X(target)을 출력
a. Disentangle-and-Compose Framework
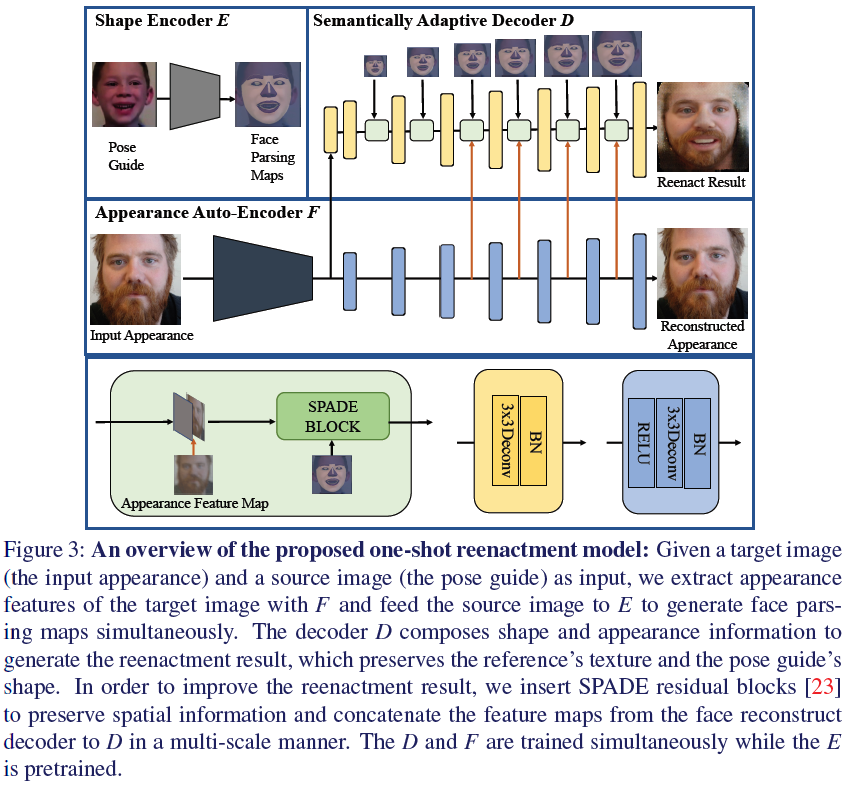
- 앞서 말한대로 Face parsing은 E(face pose Encoder)로 겉모습(appearance)는 F로
- 인코더 F에서 Decoder D로 Concat해주는 방식을 이용함 (for reduce information loss )
- SPADE(SPatially Adaptive DEnormalization) 블럭을 추가하여 adaption에 민감하게 반응함

- Shape Encoder(E)
□ Shape boudary를 학습한 모델로 얼굴모양(표정)을 segment로 추출 (WFLW dataset으로 학습했다고...)
□ Gaze(응시,눈깔) channel을 추가적으로 넣어 학습해서 segment 추출(EOTT dataset으로 학습)
□ 다른 모듈(D,F)가 학습중일 때, 이건 pre-trained라서 걍 내비둔다.
- Appearance Auto-Encoder(F)
□ Appearance Encoder(이하 F)에서는 1장의 이미지에서 표면적인 정보들을 학습한다(identity& local information)
□ x_t(F의 출력물)의 모습을 갖추게끔 학습하면서 중간중간 레이어에서 D에 concat
□ F는 shape와 independent하다 (이거 왜자꾸 나오는걸까?)
- Semantically Adaptive Decoder(D)
□ SPADE논문에서 나온거처럼 Adaption을 의식하고 SPADE block을 사용함. 그것에 대한 설명
□ 추가적으로 Pix2PixHD (이렇게되면 인용을 어디에 달아야해?)에서 나온 Multi-scale방식으로 decode
b. FusionNet
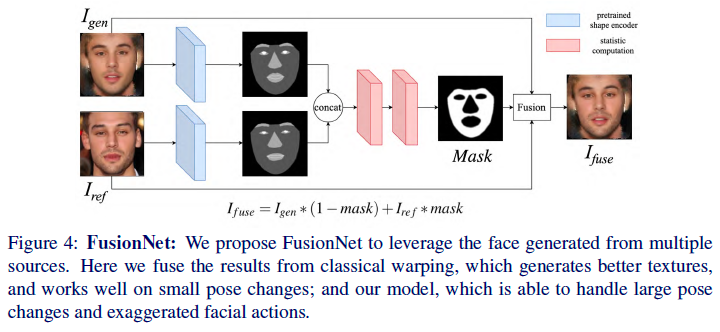
- 이미지 기반으로만 한다면 주변의 배경때문에 blurry한 결과가 나온다
- Shape 기반으로만 한다면(Segment에서 표현된 얼굴형 위주) 수염이나 주름같은 디테일이 깎인다.
- 결국 이 두 문제를 해결하기 위해 두가지 이미지 생성을 fusion하는 방식으로 결과를 냈다.
c. Learning
- 하이퍼파라미터 관련한 항목 따로 적진 않겠음
4. Experiments
a. Comparison with Single-Image Methods

- 사실 One-shot reenactment를 연구한거라서 뚜들겨패는게 당연하다
- 놀라운점은 다른 모델들도 생각보다 잘 따라간다는 것
- GANimation은 디테일면에선 훌륭하지만 중요 포인트로 언급되는 eye-gaze가 따라가질 못하는 것을 관찰할 수 있음
- 이런 정성평가는 항상 볼때마다 어찌보면 근거없이 우기는거 같다는 생각도 든다. 근데 나도 논문쓸때 그렇게 썻는데 뭐…
b. Comparison with Target-Specific Methods

- SoTA모델로 타겟잡은 ReenactGAN을 상대로 평가한다.
- 리뷰는 안했지만 아이디어 자체가 간단한 것으로부터 좋은 효과를 뽑았기 때문에 굉장히 감명깊게 본 논문인데(소스코드 달라고 메일도 보냈었다. 4개월뒤에 답장왔지만), 여기서 볼 수 있는 점은 One-shot으로 입힐 수 있다는 효율성을 어필하는듯 하다.
- 보다시피 Limited Data에서는 poor한 generate를 보여줌
c. Quantitative Results
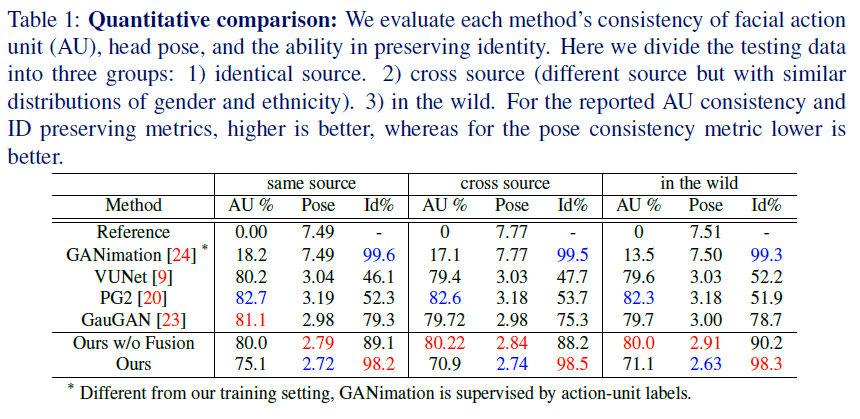
- 사용한 metric은 3가지
-
Head Pose Consistency : Head pose Estimator를 학습해서 평가했다는데, 레퍼런스도 없고 알 길이 없다.
-
Identity Preserving : 다음 모델을 학습해서 Perceptual loss를 대신해서 사용했다고 함.
- 완전 커스터마이즈 해서 한듯… 이래도 되남?
- 참고만 하는정도로 metric만 알아갑니다.
5. Conclusion
- One-shot으로만 Reenactment가 가능한 모델을 제시했다.
- 독립적으로 필요한부분만 쏙쏙 골라뽑아서 합쳐 좀 더 Detail에 다가갔다 ( FusionNet 부분)
6. My Opinion
- Eye Gaze관해서 generate 하면 어떨까? 라고 잠깐 생각하고 논문 찾아보니 역시 있는건 역시는 역시다.
- 하지만 관련해서 공부하는 입장에선 FusionNet을 도입해서 detail까지 살린 것을 보면 대단하다고 느낀다.
- Journal을 내야할텐데 이 부분이지 싶다.