- 저자 : Jessica Lee, Deva Ramanan, Rohit Girdhar
Carnegie Mellon University
- 학회 : NIPS2019(Accepted)
- 날짜 : 2019.10.10 [[paper]](https://arxiv.org/abs/1910.04742)
1. Introduction
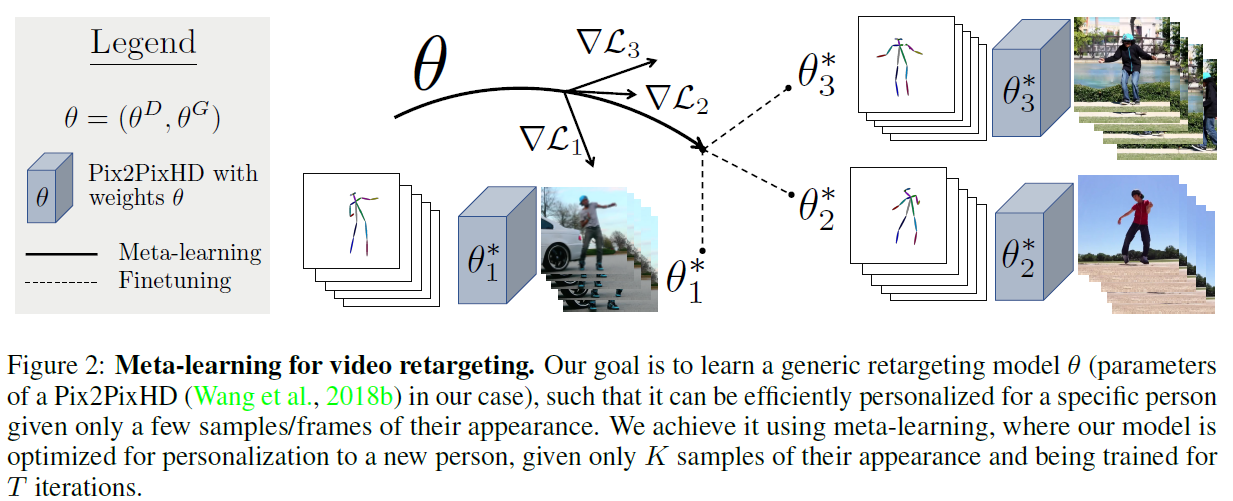
- 본 논문의 목표는 몇장의 샘플로 특정 대상과 환경에 적응하여 인간의 모션을 생성하는 방법을 배우는 모델을 개발 하는 것.
- 다양한 Related work가 있고 그 중에 유명한 논문이 대다수 (EDN, LargeGAN, MoCoGAN 등)
- Meta Learning을 사용한 이유는 어떤 것이 가장 best fine-tune(Personalize: 개인화인데 여기서는 특정 인물이 들어가 그에 걸맞게 튜닝이 되어야 하니까 그런식으로 쓴듯)인지 금방 찾게되고, 이러한 기법을 사용하면 few-shot으로도 적응이 빠르기 때문이라고.
- few-shot으로 잘 adaption(personalization)하는 것이 가장 중요한 task
2. Related works
- FewShot Learning : Meta learning을 통해 극한으로 optimize된 모델을 학습한다면 몇장 되지 않는 사진으로도 원하는 출력물을 얻어낼 수 있다고 이해했음
- Meta Learning : 사람이 어떤일을 가능하게 하기 위해 빠르고 효율적으로 일을 배우는 것 처럼, Meta Learning도 마찬가지로 생각하면 된다. 다양한 방법들이 있지만 여기서는 다루지 않을 예정, 가장효율적인 논문 하나 레퍼런스 달아둔다 , Reptile , [paper]
3. Our Approach (Proposed Method)
- 목표를 말하는데 아까 말한것과 같다.
- 아싸리 Speed 와 Efficiency를 파라미터로 상정하고 접근한다 ○ Computation/Iterations : T ○ number samples required for personalization : K
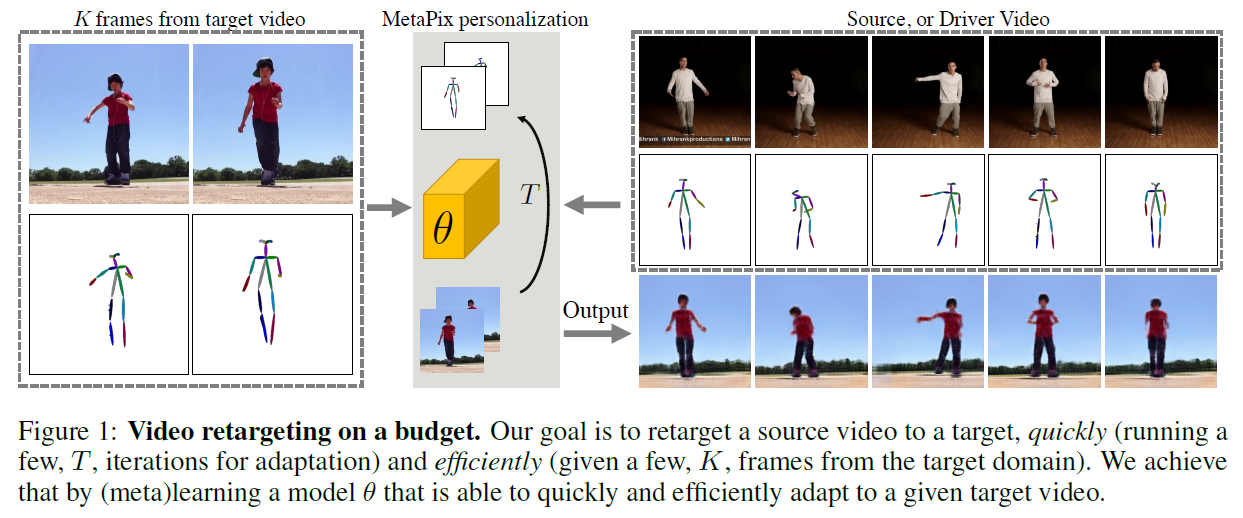
a . Best Retargeting Architecture
○ 2가지의 approach 제안
i. 어떤 것에서 다른것으로 transformation 하는 것을 learning 하는 것 (Zho et al , 2019 [[paper]](https://arxiv.org/pdf/1904.00129.pdf))
ii. Pose 이미지에 RGB를 Mapping하는 것 -> Pose2Im (Everybody Dance Now : [[paper]](https://arxiv.org/abs/1808.07371))
○ 둘 다 읽어본 것, 두 방법 모두 스피드와 효율에 제약에 만족하는 모델이다 이건가
○ 두 방법중 2번째 : Pose2Im K frames를 사용해서 Pose2Im 매핑의 경우 다른 모습으로 나타나고
○ 두 방법중 1번째 : Transformation하는 것은 kC2의 페어 이미지를 사용하지만 옵티마이즈 할때는 다른 논의가 필요하다. (뭐라는거냐)
○ Pose2Im(EDN) 방법
i. 기존 방법과 다 똑같음 자세하게 설명함
ii. Pix2PixHD를 쓴 것까지 그냥 아주 똑같음. 바꾼것 없다 이말이야 [[review]](https://realdr4g0n.github.io/Everybody-Dance-Now/) #### ○ Pose Transfer 방법
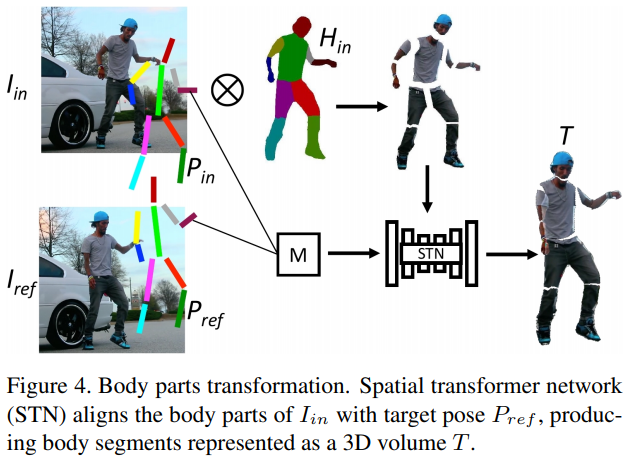
i. 이 방법은 팔다리를 다 분리하고 목표와 결합한 후 배경에 삽입하는 방식임 (U-net을 이용)
ii. Pose Transfer와 Posewarp 모델을 사용합니다. (안 읽을거라 레퍼런스 안달음)
b. MetaPix